In part 1, we scraped for data off Boardgamegeek (BGG). Part 2 saw us making predictions off the ratings matrix with 5 models and evaluating offline through RMSE and top 20 lists recommended for me.
In this final installment, we will be building a web app using flask, a microframework based on python and deploying it via an Amazon EC2 instance. The aim is to get online evaluations from users of BGG.
We will be employing recommendations from 3 algorithms, namely SVD with 50 latent factors (SVD50), Non-negative matrix factorizaiton (NNMF) with 10 latent factors and the Cosine Similarity neighbourhood method.
Developing the flask app
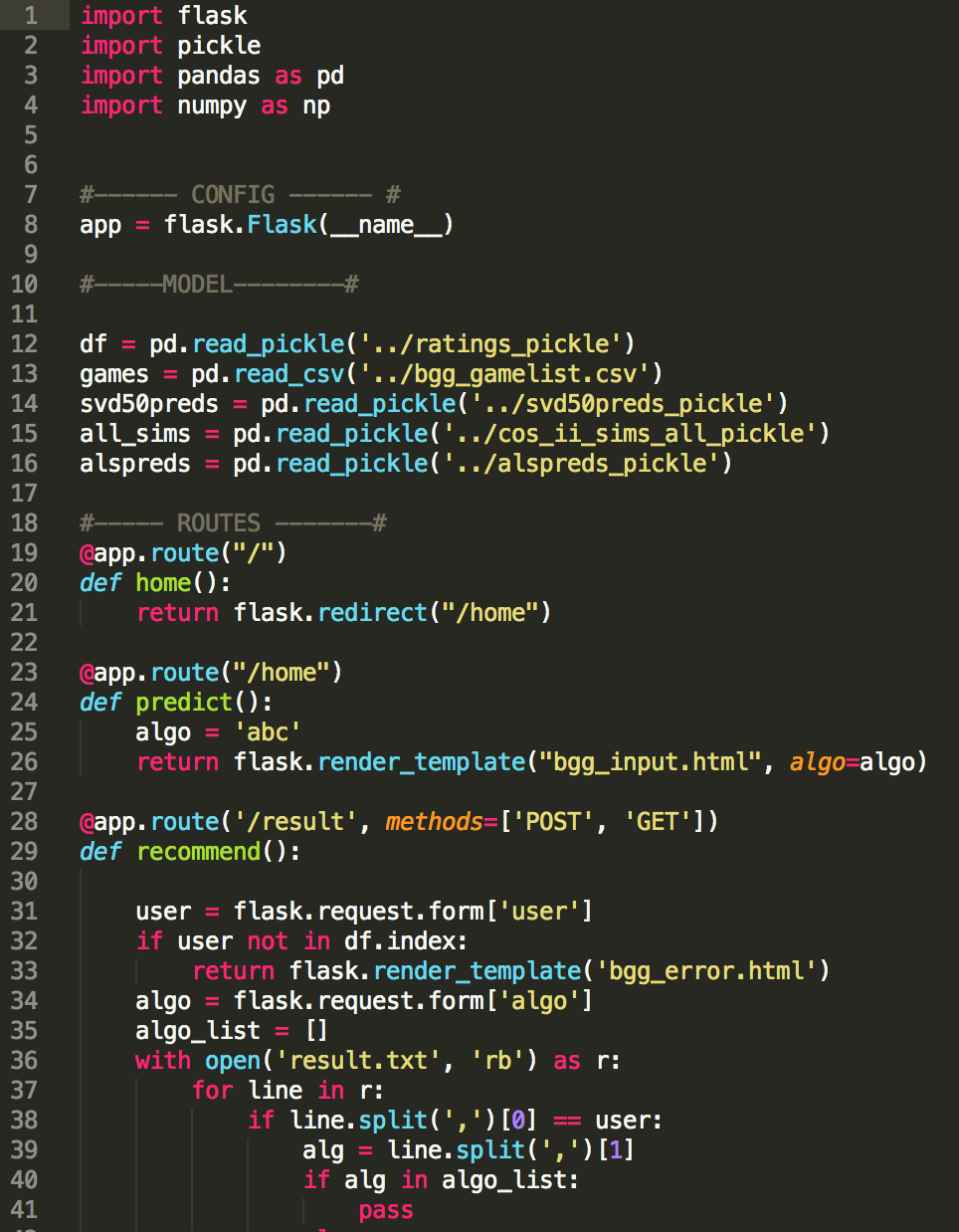 A snapshot of the controller file
A snapshot of the controller file
Flask makes use of the MVC framework in web development to deploy small, lightweight web apps that are based on the Python language. Although it can also be used for larger scale settings, it is generally not considered a production-level tool. Nevertheless, it is well-suited for our purpose.
The controller.py file seen above controls the logic of how your html files are routed from one webpage to the next. The first thing to do is to import flask, followed by the following config command app = flask.Flask(__name__). You can also choose to import certain modules from flask, which means you do not have to consistently type in the flask instance every time you perform a flask related function.
If you look at the diagram above, the routes section of the controller file contains similar @app.route commands that control which html page gets rendered once it’s called. Here’s a sample of the route function that controls the logic for my Contact page.
@app.route('/contact')
def contact():
return flask.render_template('bgg_contact.html')
The function is called into action whenever the <a> tag that directs to the ‘/contact’ webpage is triggered. It will then render the appropriate html template for that page under its render_template function.
 Example of header tag of each html page, where the
Example of header tag of each html page, where the <a> tag links to the Home, About and Contact pages
The contact html contains the following code under a <main tag that asks the user for input.
<main role="main" class="inner cover">
<form action="/feedback" method="POST">
<h1 class="cover-heading">Got feedback?</h1>
<div class="form-group">
<input class="form-control" type="text" name="username" placeholder="BGG Username" id="username" required="true">
</div>
<div class="form-group">
<textarea class="form-control" id="feedback" rows="6" name="feedback_input" placeholder="Leave a note!" required="true"></textarea>
<p class="lead">
<p><input class="btn btn-lg btn-secondary" type="submit" value="Submit" /></p>
</p>
</div>
</form>
</main>
If you’d notice, the <form> tag contains the attribute action="/feedback". Upon successful user input, the next page to render is the ‘/feedback’ webpage. Going back to our controller file, our routing command defines a function to write the input into a txt file and to render the feedback html template
@app.route('/feedback', methods = ['POST', 'GET'])
def feedback():
if flask.request.method == 'POST':
user = flask.request.form['username']
fdbk = flask.request.form['feedback_input']
with open('feedback.txt','a') as f:
f.write(user + ',')
f.write(fdbk + '\n')
return flask.render_template('bgg_feedback.html')
The model section of the controller.py file houses the pickled and csv files that will be used to pass in as input into our recommend functions. These include the main ratings matrix, along with pre-calculated predictions of the SVD50 and NNMF models as well as the item-item similarity matrix from part 2.
The main bulk of the app’s intelligence comes from the recommend function where it gets called several times depending on where the user has progressed on the app. The recommend function in the flask app is essentially a combination of the 3 recommend functions derived from the individual classes in my modeling work, tweaked to activate when certain conditions are met in the course of the flow of the app. You may delve deeper into the code at my Github repo.
At this point, it seems appropriate for me to talk about the flow of the app and what a user is prompted to do.
App flow
 Homepage
Homepage
This is where a user would start. First, in order to get results, they need to have an account on the Boardgamegeek website, and have rated at least 10 games as of 13th October 2017, the date where I had finished scraping the data. After entering a valid username, they will be brought to the first list which was generated for them via the SVD model with 50 latent factors.
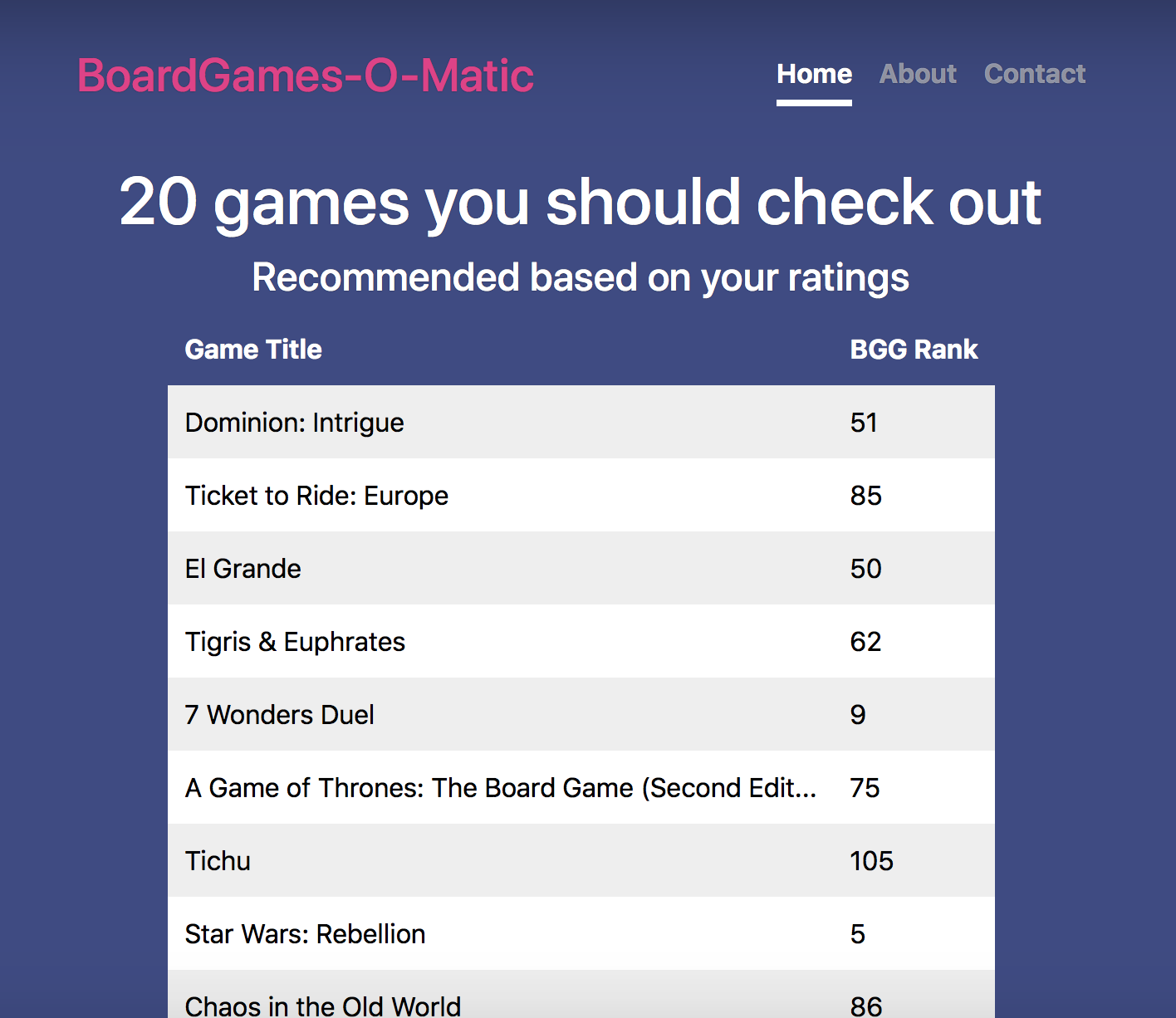 Top half of top 20 list
Top half of top 20 list
Once they scroll down, they will be prompted to rate the list.
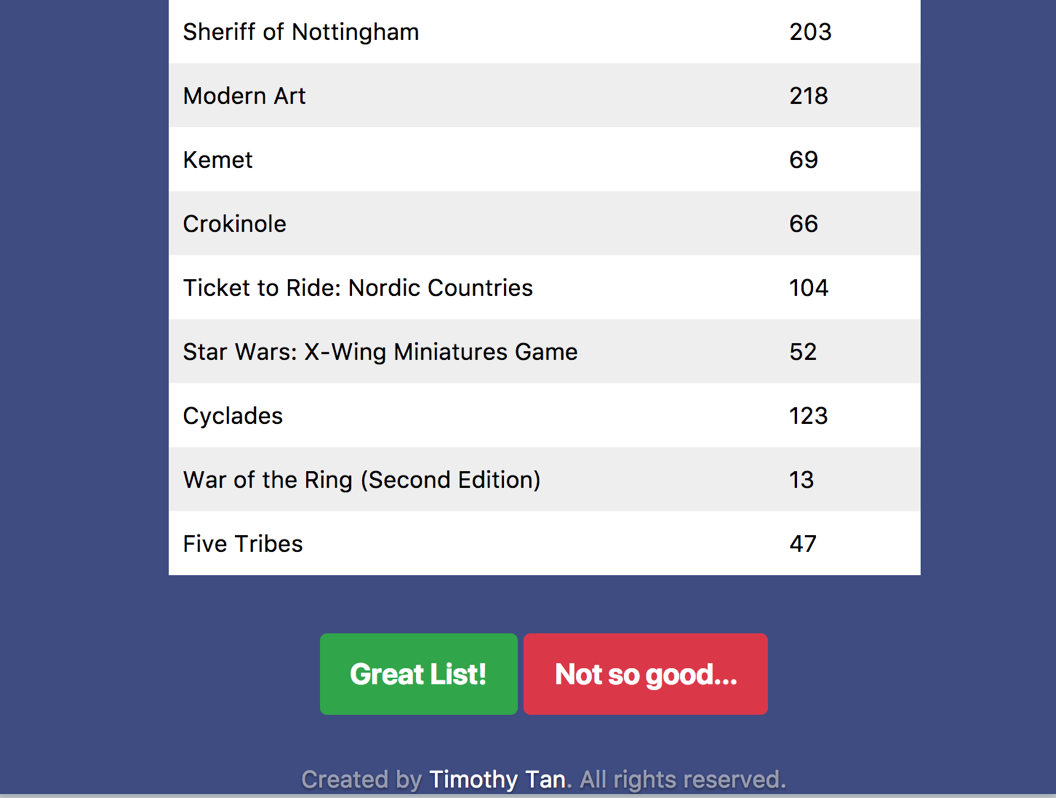 Yay or nay
Yay or nay
After rating, the user will be brought to a screen that will explain what method their list was generated from and will be prompted to click on the button below to generate a new list. The order of model generation is first SVD with 50 factors, then NNMF with 10 factors and finally Cosine Similarity.
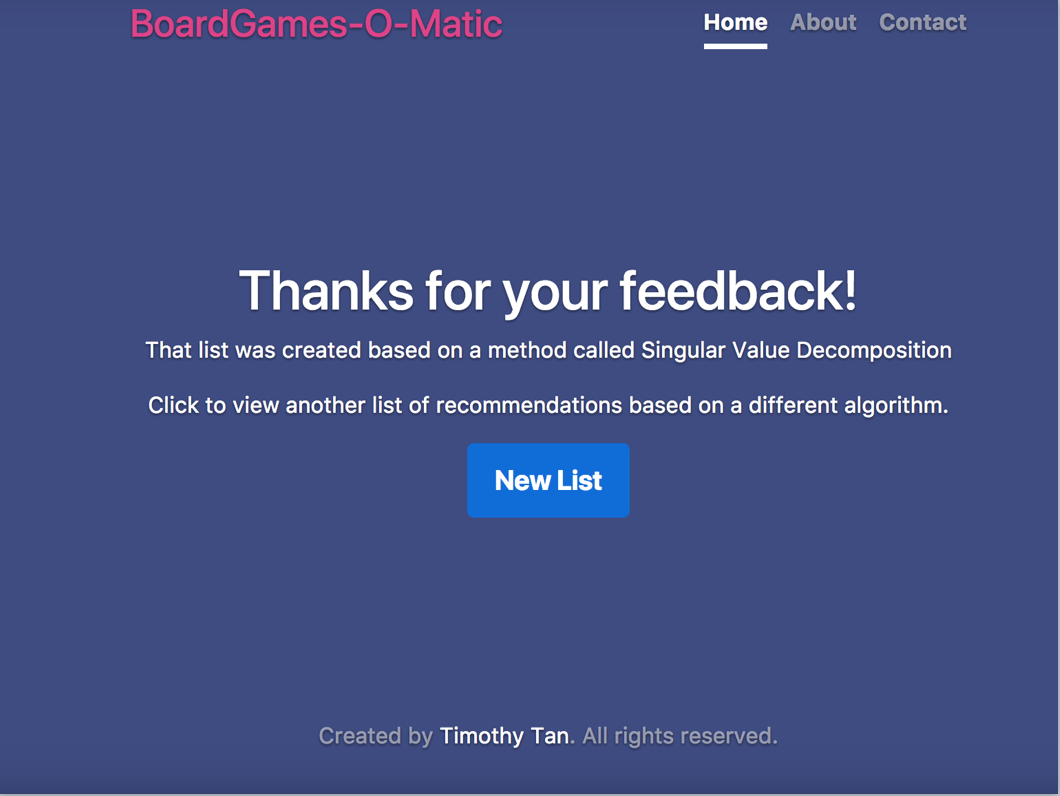 Explains the method used and prompts the user to dive in for more
Explains the method used and prompts the user to dive in for more
Once a user has gone through all 3 lists, they will be brought to a page where they are able to revisit the lists again. The only difference is that they will not be able to re-rate them.
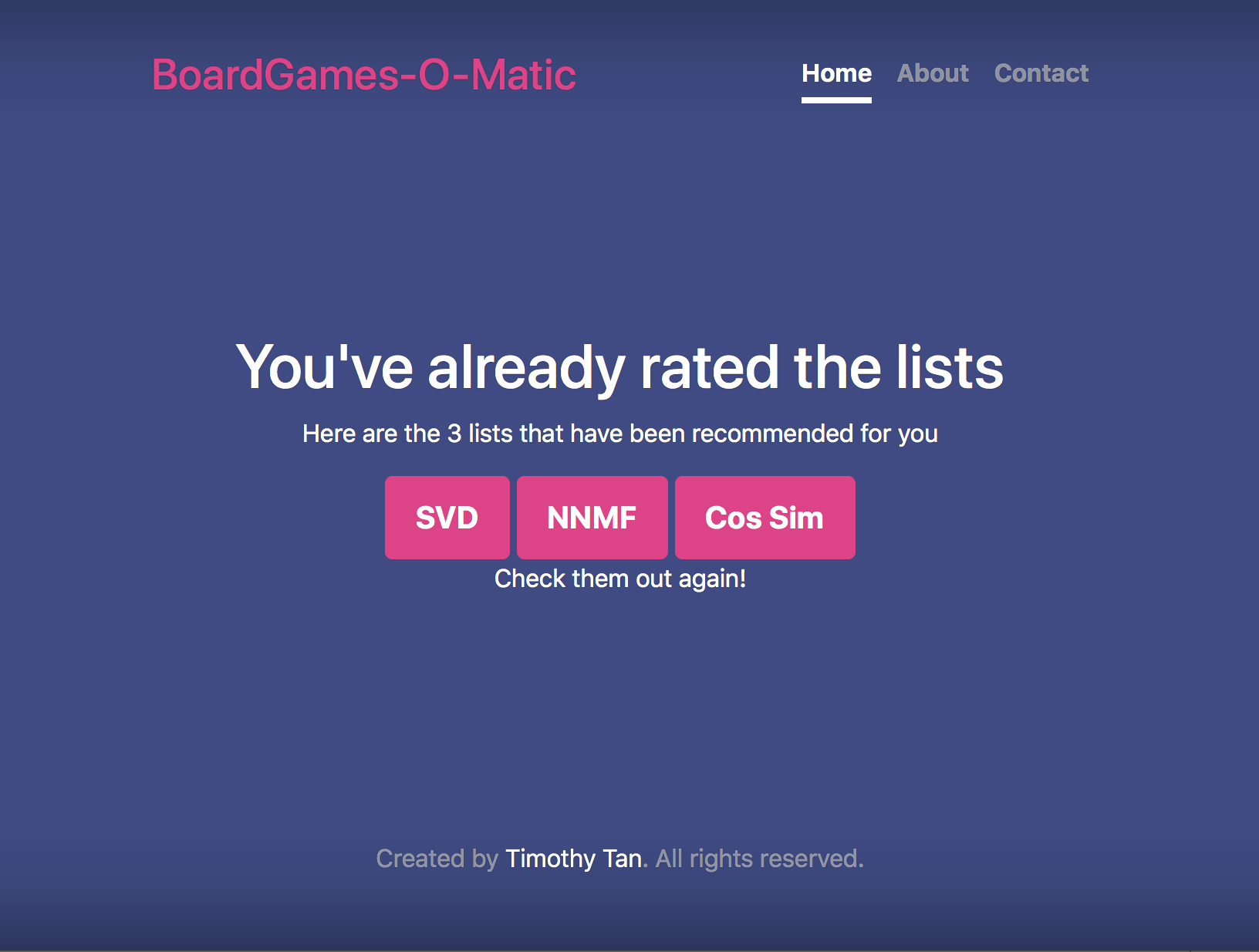 Check them out again.
Check them out again.
The ratings are stored in a txt file whereby the username and their rating for the model are comma-separated. The ratings are encoded to be 1 for liked the list and 0 for did not like the list.
One major issue I’d encountered while developing the app was in how variables are passed from the html page to the controller file and back again to another html page. I had to make use of hidden input tags on several html pages just to contain these variables for use further down the line.
Also, while it may seem trivial on the frontend, getting the logic to flow correctly while keeping the number of html templates to a minimum took some time. For example, I wanted users to be able to access the lists after they have rated all three but not be able to rate them again. In order to do so, I had to write a jinja if-else statement in the html code that checks to see the boolean condition of a particular not_done variable in the controller file which decides what to display onscreen.
Deploying the app
As we have some amazon credits given to us, I decided to put my web app up on an AWS EC2 instance. Unfortunately, as my 3 pickled files were at least 1.6GB in size, I’ve had to opt for a large vCPU instance with 16GB RAM and 4 vCPU cores.
The app’s files are stored in a github repository where they are synced automatically between the AWS servers and Github’s via a bash script utilizing crontabs.
Marketing and getting feedback
I wanted to test the app out in the real world and posted a message on the BGG website itself under the Recommendations forum. The response was beyond what I had expected.
 Simple and honest message
Simple and honest message
I received over 240 unique users testing the app in 3 days and an approval rating of 74.58% (179 users liked at least one of the list).
Another metric I’d evaluated was how many user actually went through the flow and rated all 3 lists. A rather dismal 59.16% or 142 users showed that my UX design probably needed a bit more work.
The main area of interest however was how the models fared in terms of approval from the 142 users.
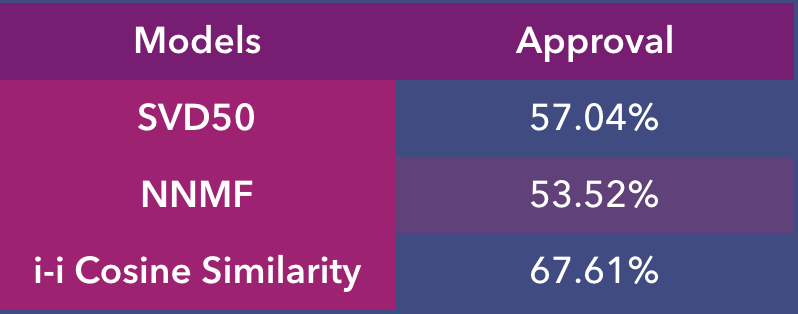
As can be gleaned from the results above, both the SVD50 and NNMF models did slightly better than average but the best model was clearly the item-item cosine similarity one.
The one good thing about this community of geeks is in how forthcoming they are in providing feedback, and I got it in droves through the forum post I’d created.
It didn’t start off well though.
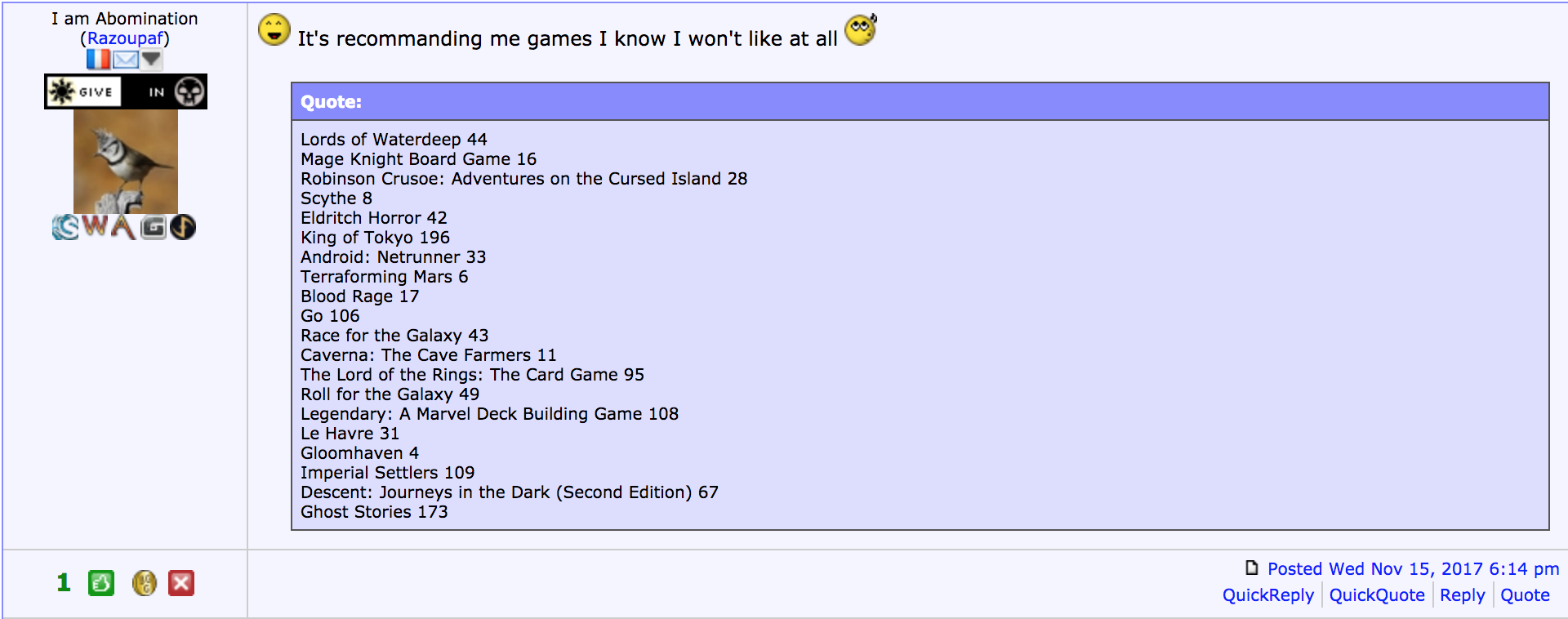

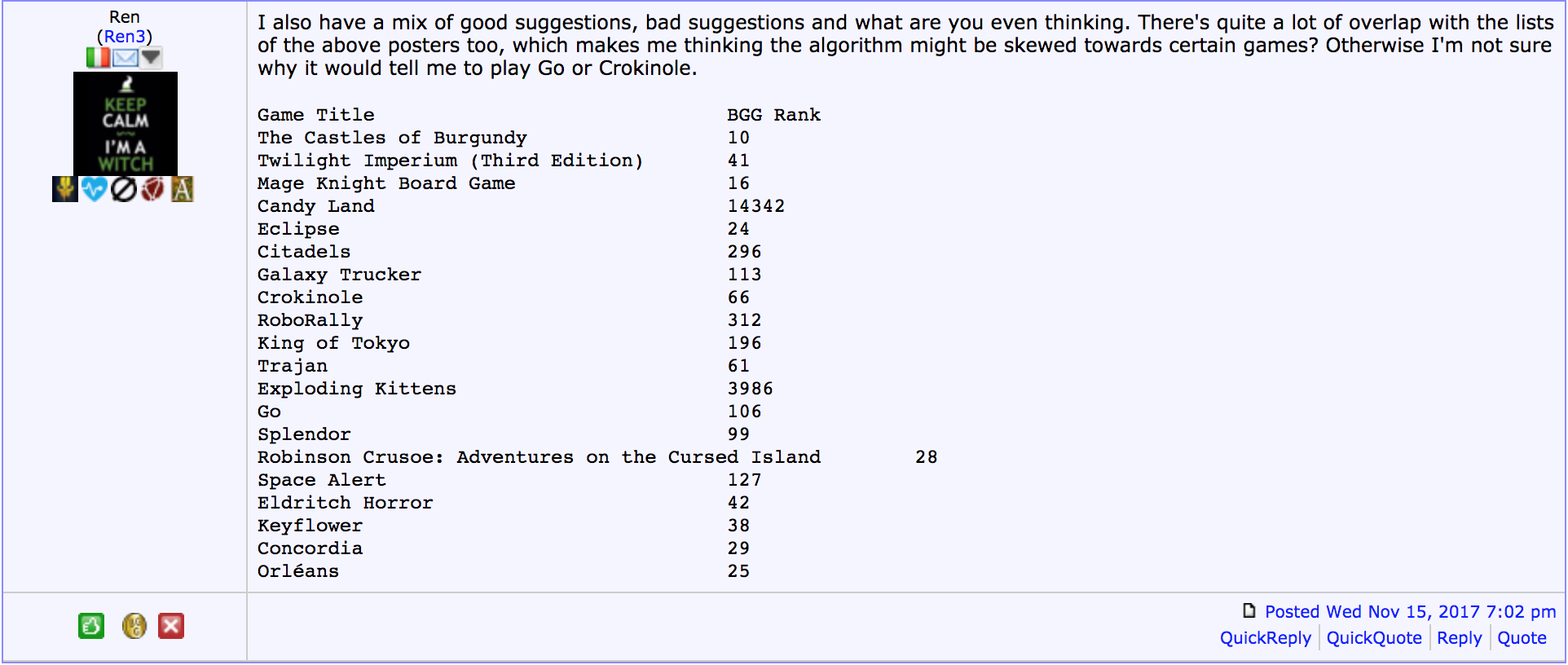
But then the aha moment.


It seems that the reason why the list based off the SVD50 model was so disliked was because it recommended games at the bottom of the rankings too.
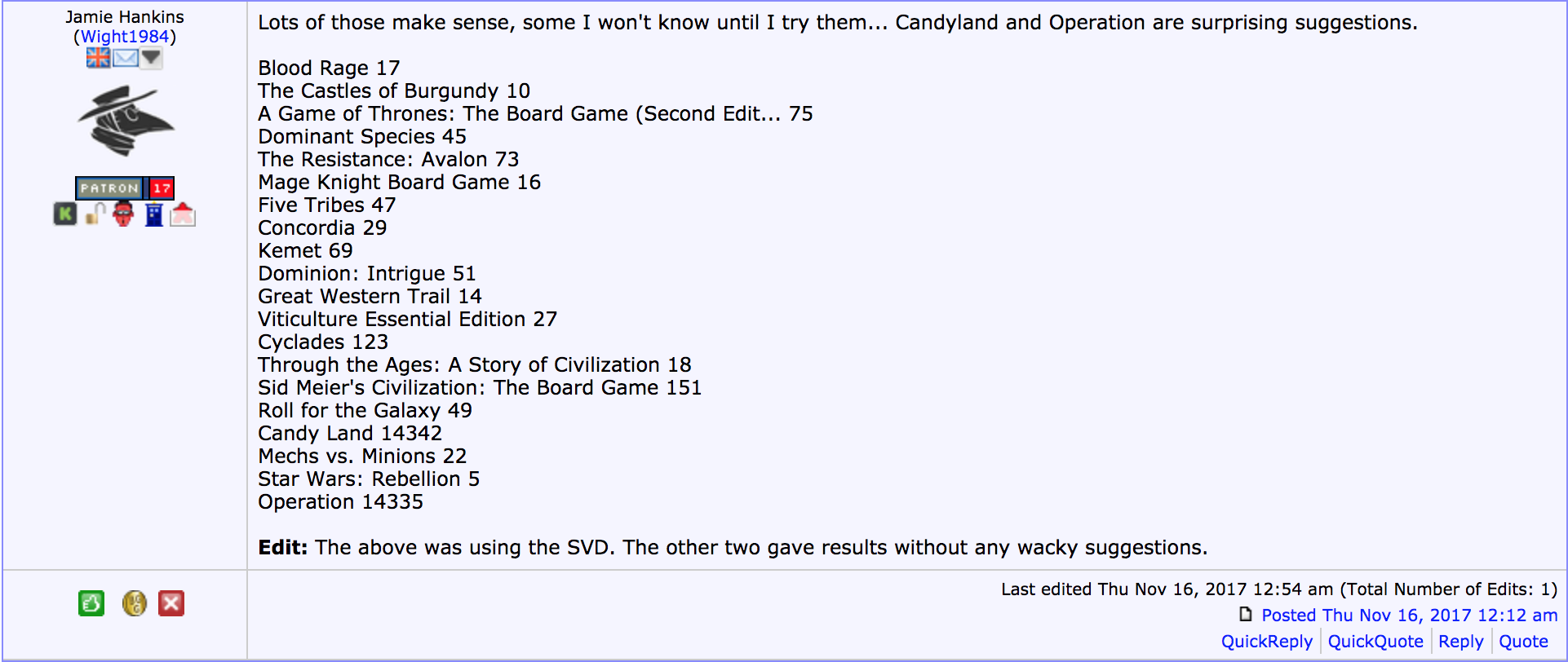
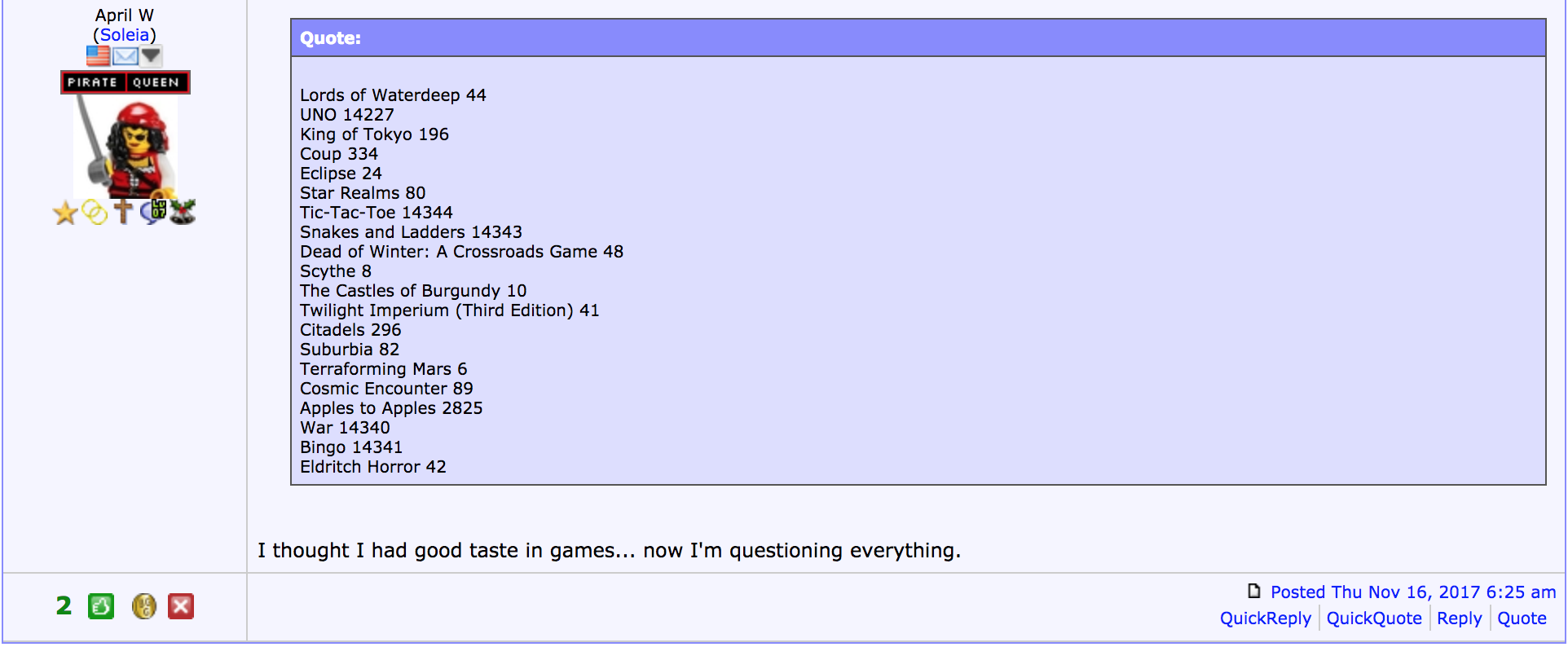 She didn’t rate beyond the first list too!
She didn’t rate beyond the first list too!
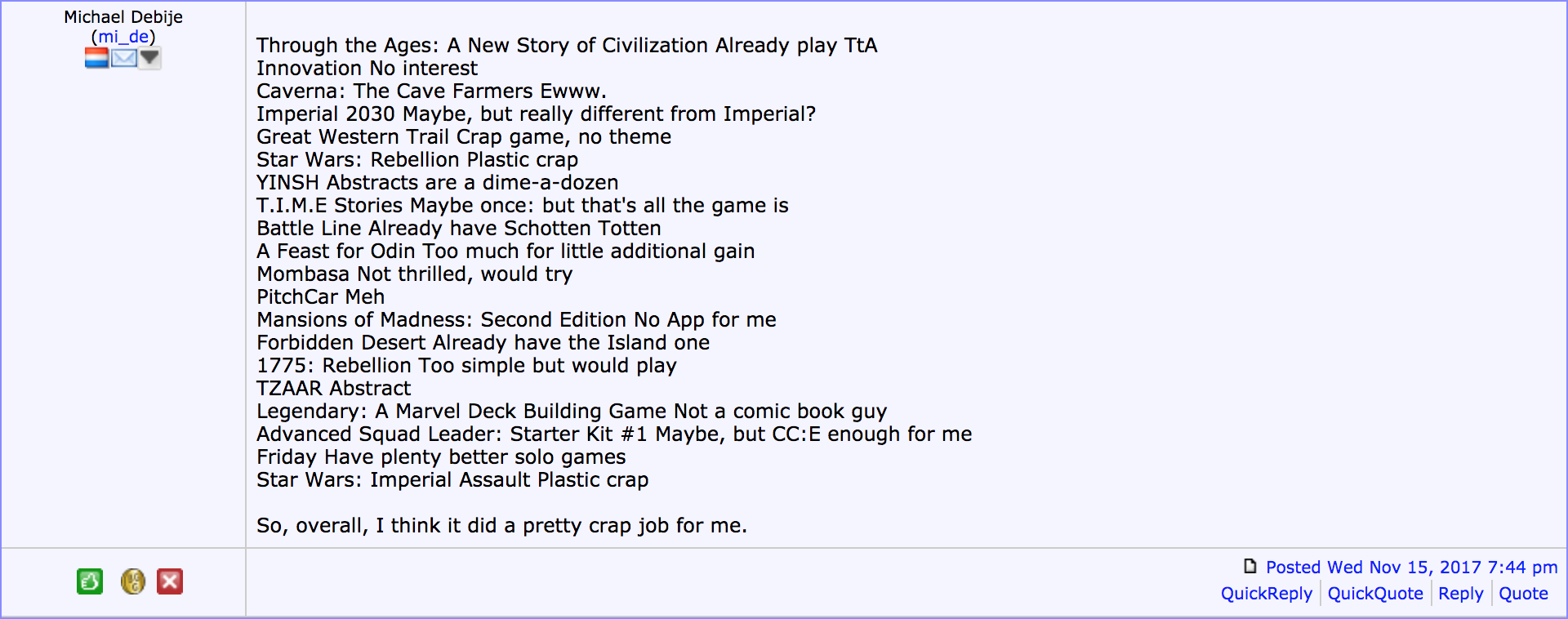
But the most telling comments were the following.


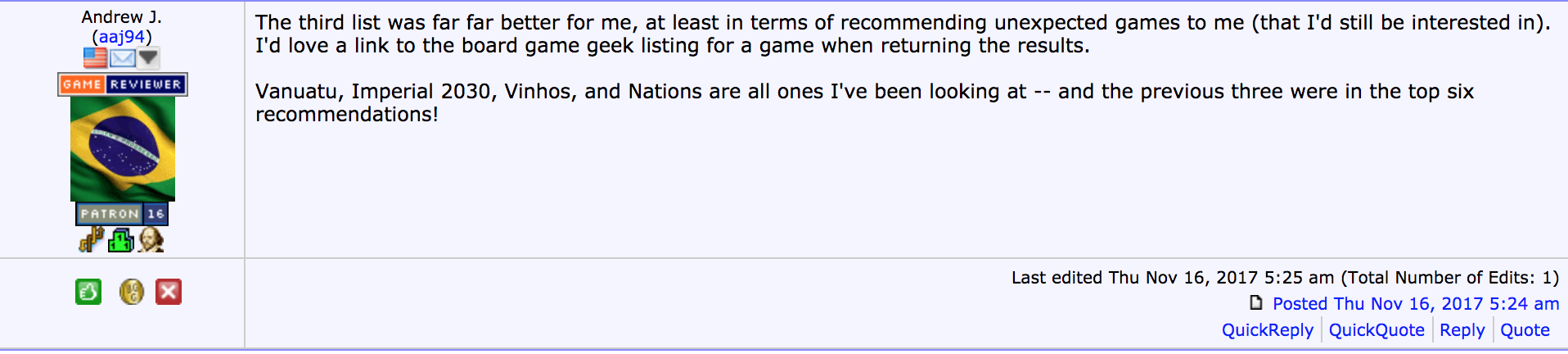
The item-item cosine similarity list gave the most creative and unexpected list of games as it looks at the similarity in ratings across games and reached further into the lower ranks of games for a greater diversity of options.
Other than having universally-panned, low-ranked games turn up unexpectedly in both the SVD50 and NNMF lists, their tendency to only recommend the most popular games seem to be distasteful for some.

You can view the entire forum post here.
The workings to obtain the approval rating values of the 3 models can be found here. In it I extracted the results from a comma-separated txt file into a dataframe, performed some deduplication work, then pandas groupby operations and pivot_tables to extract the necessary information.
Conclusion
In this post, I explained how I developed my web app through the flask microframework, detailing the logic flow as well as getting it online. I also revealed the results of my online findings and showed how the comments on the forum post where I marketed the app on corroborated with my findings on the approval ratings for the lists generated by the 3 differnet models.
Even though the cosine similarity model had received the lowest RMSE score through offline evaluations, the diversity of recommendations proved it to be the most popular one, beating out the lists generated through supposedly better latent factor algorithms.
One surprising thing out of the online evaluations was how both latent factor model seemed to present extremely low-ranked games in certain users’ top 20 lists. I surmise that this could be due to how the algorithm simply creates low-rank reprentation of the ratings matrix which is highly dependent on the number of latent factors chosen. These latent factors are often times unexplainable, rendering matrix factorization methods a bit of a ‘black box’ when it comes to explaining their recommendations. I suspect that by overspecifying the number of latent factors, the low-ranked games are grouped together with the high-ranked games on some unexplained dimensions, resulting in miscalculations in the predicted ratings. Further analysis should be conducted in this area of optimizing for latent factor selection.
Future work
This app was developed within 4 days by a complete newbie in web development and due to the need to deploy it quickly to gather the online evaluations, not all ideas were implemented:
-
Storage of the input data should be in a database so as to reduce the storage and processing cost involved in handling pickled files. For reference, the 3 pickled files are 1.7GB each in size.
-
I was trying to figure out how to create a final multiple choice question for the user to select the best list out of the 3 but could not do so in time.
Some potential extensions to this project includes:
-
Extending the gamelist beyond the 1807 to include games with less ratings
-
Evaluate with rank metrics eg: Mean Average Precision @ K
-
Tweak the flask routing and algorithms to be able to access real-time ratings based on API call in order to provide recommendations that are more current.
-
Assess a computationally less expensive approach to user-user cosine similarity. User-user similarity helps in generating serendipity and seeing as to how the item-item approach does so well in providing unexpected recommendations, it would be interesting to see how different the user-user approach would be. One way to alleviate the high computational cost would be to perform unsupervised learning first to identify nearest neighbors before calculating similarity scores.
-
Model with a graph-based network like neo4j
-
Explore group recommendations. Board games are mostly played by 2 or more people and a recommender that takes into account the preferences of all parties involved might be well regarded.
-
Include content-based filtering to reduce cold start problem for new games.
-
Create context aware recommendations, possibly in the form of a chat bot, that instead of recommending new games, recommends you games to bring to the next game night by asking you a series of questions
This is part 3 of a 3 part series on building a board game recommender system for Boardgamegeek.com users. Part 1, where we scrape for ratings and perform preprocessing work can be found here. Part 2, where we model and predict the recommendations can be found here.
The accompanying ipython notebook can be found in the following Github repo.